

Table of Contents
Dans le vaste univers de l’intelligence artificielle, une affaire récente fait grand bruit : la start-up chinoise Deepseek est accusée par OpenAI d’avoir mis à profit les réponses de ChatGPT et d’autres modèles propriétaires pour entraîner son propre modèle concurrent. On parle ici de « distillation », une pratique technique, mais aussi d’un litige qui pourrait redessiner les règles du jeu en matière de propriété intellectuelle et de concurrence. Qui a raison ? Deepseek a-t-elle enfreint les conditions d’utilisation d’OpenAI ? Et quelles leçons la communauté IT peut-elle en tirer ?
Le Contexte : Une Accusation Qui Secoue l’IA
Deepseek et l’« Emprunt » de la Technologie OpenAI
OpenAI, l’une des firmes pionnières dans l’IA générative, accuse Deepseek d’avoir envoyé des millions de requêtes à ChatGPT (et autres outils OpenAI) pour recueillir des réponses, puis s’en être servie pour entraîner son propre modèle, désormais open source. Cette technique est connue sous le nom de « distillation » : un grand modèle (professeur) sert de référence à un modèle plus petit (élève), qui apprend en imitant ses réponses.

Le nœud du problème réside dans les conditions d’utilisation d’OpenAI, qui interdisent clairement de développer un modèle concurrent à partir des réponses de ChatGPT. L’entreprise américaine menace donc d’entamer des poursuites, affirmant disposer de preuves solides de ce « détournement ».
La Preuve Troublante
Une capture d’écran, très relayée sur les réseaux, montre Deepseek se présenter comme un « grand modèle de langage développé par OpenAI ». Après avoir supprimé cette mention, Deepseek a remplacé le nom OpenAI par le sien, ce qui nourrit les soupçons. Pour OpenAI, ce changement attesterait que le modèle chinois a récupéré du texte et des connaissances sans autorisation.
Des Conséquences Économiques et Médiatiques
Les prouesses de Deepseek suscitent un vif intérêt. Comment une start-up chinoise, jusqu’ici peu connue, est-elle parvenue si rapidement à rivaliser avec des géants comme OpenAI et Nvidia ? Cette percée remet en question la frontière entre concurrence légitime, espionnage industriel et respect des règles. Sur les marchés financiers, la question se pose : si la distillation s’avère avérée, comment OpenAI ou d’autres leaders pourront-ils se protéger ?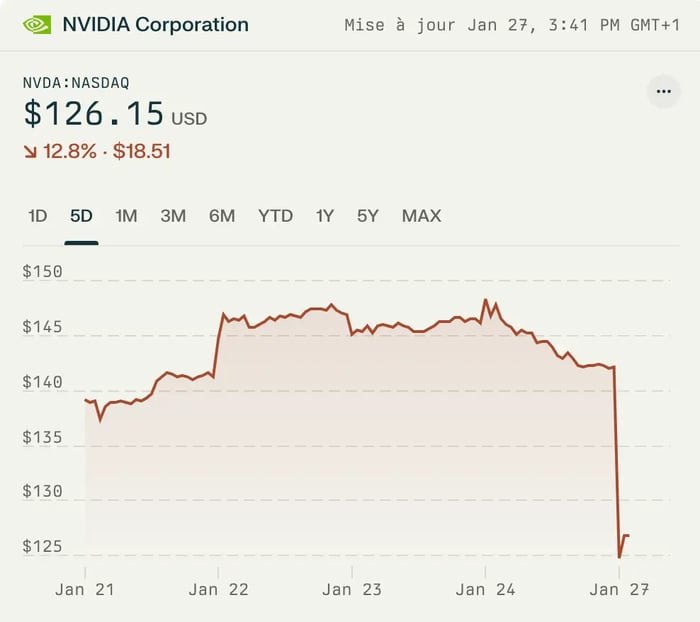
Comprendre la Distillation de Modèles
Pour saisir la portée de ce litige, il faut maîtriser le principe de la distillation en IA. Imaginez un maître artisan apprenant à un apprenti à fabriquer des meubles. L’apprenti observe, imite et finit par reproduire les mêmes gestes, jusqu’à obtenir un résultat presque équivalent. En IA, c’est la même chose : on pose des questions à un grand modèle (le professeur) pour en récupérer les réponses, que l’on donne à un modèle plus petit (l’élève). Progressivement, l’élève acquiert la même connaissance tacite, sans avoir eu besoin de réentraîner tout un réseau depuis zéro.
L’avantage : un modèle distillé coûte moins cher à exécuter et peut atteindre des performances comparables dans certains domaines précis. Dans l’affaire Deepseek, c’est précisément cette technique qui est mise en cause : la start-up aurait « abusé » de l’interface de ChatGPT pour récupérer massivement des données et créer son propre modèle, en violation des conditions d’OpenAI.
Les Limites Légales et l'ironie
Les Terms of Service d’OpenAI stipulent qu’il est interdit de former un produit concurrent à partir de ses sorties. Pour prouver la violation, il faudrait démontrer que Deepseek n’a pas seulement utilisé ChatGPT à grande échelle pour de la recherche ou des tests, mais l’a fait en vue de reproduire ses compétences. Sur le plan juridique, la situation est inédite : peu de réglementations spécifiques existent autour de la « reproduction » d’un modèle via ses réponses.
Nombre d’observateurs rappellent qu’OpenAI a entraîné ses propres modèles sur d’immenses corpus publics (articles, livres, sites web) sans verser de compensation aux ayants droit. En revanche, ChatGPT reste un service propriétaire : ses réponses ne sont pas libres de droits. Pour OpenAI, la comparaison n’est donc pas valable.
Malgré tout, le débat met en lumière un paradoxe : les leaders de l’IA se sont eux-mêmes appuyés sur des données ouvertes, tout en entendant protéger leurs productions finales de toute utilisation commerciale non autorisée. Cette tension témoigne du manque de cadres juridiques adaptés à l’économie numérique et à l’explosion de l’IA.
Les Performances de Deepseek : Un Concurrent à Prendre au Sérieux
Sur certaines plateformes d’évaluation à l’aveugle (comme LMSys), Deepseek rivalise avec ChatGPT. Les utilisateurs, ne sachant pas qui produit la réponse, jugent parfois Deepseek meilleur ou équivalent. Toutefois, sur des tâches plus complexes, notamment celles exigeant un raisonnement approfondi, Deepseek se révèle moins performant.

Les résultats confirment que la distillation permet d’approcher la qualité d’un grand modèle à moindre coût, mais ne garantit pas une performance optimale dans tous les cas. Deepseek reste néanmoins un exemple frappant de start-up capable de réaliser un bond technologique majeur en très peu de temps.
Un Enjeu Géopolitique entre la Chine et les États-Unis
Cette affaire ne se limite pas à un conflit entre deux entreprises. Elle reflète la rivalité croissante entre la Chine et les États-Unis pour la suprématie technologique. Les deux puissances investissent massivement dans la recherche en IA, considérée comme un levier clé pour la compétitivité économique et la sécurité nationale.
Deepseek, en tant que start-up chinoise, reçoit potentiellement des soutiens importants d’investisseurs privés et, selon certaines rumeurs, de subsides publics. Les Américains, de leur côté, soutiennent également leurs fleurons technologiques (Microsoft pour OpenAI, Google pour ses propres modèles). Le bras de fer commercial prend ici une tournure stratégique : les gouvernements surveillent de près toute avancée ou tentative de copie, consciente ou non.
Vers une Redéfinition des Règles du Jeu ?
Sur le plan technique, il est difficile d’empêcher un utilisateur de poser un grand nombre de questions à un modèle comme ChatGPT. Les entreprises peuvent mettre en place des quotas d’utilisation, analyser le comportement des requêtes ou facturer très cher au-delà d’un certain volume. Pourtant, ces restrictions risquent d’impacter aussi les start-up qui utilisent ChatGPT de façon légitime, pour développer de nouvelles solutions.
La véritable question est de savoir dans quelle mesure la distillation enfreint la loi ou les règles de concurrence. Tant qu’aucun cadre juridique clair n’existe, les litiges se régleront au cas par cas. De futures décisions de justice sur ce type d’affaire pourraient clarifier la notion de propriété intellectuelle appliquée aux sorties d’un modèle d’IA.
L’affaire Deepseek illustre la rapidité avec laquelle de nouveaux acteurs peuvent émerger dans l’IA, en tirant parti, parfois de manière controversée, des modèles déjà existants. Cette « distillation » repose la question de la propriété intellectuelle : jusqu’où peut-on exploiter les sorties d’un outil propriétaire pour en créer un autre ? Faut-il renforcer la réglementation, au risque de brider l’innovation ?
Au-delà du débat purement technique, l’opposition entre une start-up chinoise et un leader américain rappelle le contexte géopolitique d’une compétition farouche pour l’excellence technologique. Les développeurs, chercheurs et entreprises d’IA évoluent dans un paysage en pleine mutation, où chaque avancée fait l’objet de suspicions, de controverses et de rivalités stratégiques.
A mon avis : qu’on parle de distillation ou de modèles d’IA de nouvelle génération, ce secteur a encore de nombreux défis à relever. Pour la communauté IT comme pour les instances légales, l’enjeu sera de trouver un équilibre entre la libre circulation des idées, la protection des innovations et le maintien d’une concurrence saine. L’avenir de l’intelligence artificielle se décide maintenant, et il se jouera autant dans les laboratoires de recherche que dans les salles de tribunal.
Qu’en pensez-vous ? Donnez votre avis et votez ci-dessous ! 👇
📊 Sondage : Votre Avis Compte !
L’affaire Deepseek vs OpenAI soulève des questions essentielles sur la propriété intellectuelle et la concurrence dans l’IA. Alors, vous en pensez quoi ?
🔹 Deepseek a-t-elle dépassé les limites ?
✅ Oui, c’est une violation des règles d’OpenAI.
⚖️ Non, c’est une concurrence légitime.
🤖 Peu importe, l’IA doit être open-source.
❓ Je ne sais pas, j’aimerais en savoir plus.
🗳️ Votez et partagez votre avis en commentaire ! 💬👇


